
이전까지 indeed의 정보들을 가지고왔다면 이번에는 stackoverflow의 정보들을 가져오고 main.py를 수정해서 csv파일을 만들 준비를 하자.
main.py
from indeed import get_jobs as get_indeed_jobs
from so import get_jobs as get_so_jobs
from save import save_to_file
indeed_jobs = get_indeed_jobs()
so_jobs = get_so_jobs()
indeed.py
import requests
from bs4 import BeautifulSoup
LIMIT = 50
URL = f"https://kr.indeed.com/jobs?q=python&limit={LIMIT}"
def get_last_page():
result = requests.get(URL)
soup = BeautifulSoup(result.text, "html.parser")
pagination = soup.find("div", {"class": "pagination"})
links = pagination.find_all('a')
pages = []
for link in links[:-1]:
pages.append(int(link.string))
max_page = pages[-1]
return max_page
def extract_job(html):
title = html.find("h2", {"class": "title"}).find("a")["title"]
company = html.find("span", {"class": "company"})
company_anchor = company.find("a")
if company_anchor is not None:
company = str(company_anchor.string)
else:
company = str(company.string)
company = company.strip() # 빈칸을 지워줌
location = html.find("div", {"class": "recJobLoc"})["data-rc-loc"]
job_id = html["data-jk"]
return {
"title": title,
"company": company,
"location": location,
"link": f"https://kr.indeed.com/viewjob?jk={job_id}"
}
def extract_jobs(last_page):
jobs = []
for page in range(last_page):
#print(f"Scrapping indeed page:{page}")
result = requests.get(f"{URL}&start={page*LIMIT}")
soup = BeautifulSoup(result.text, "html.parser")
results = soup.find_all("div", {"class": "jobsearch-SerpJobCard"})
for result in results:
job = extract_job(result)
jobs.append(job)
return jobs
def get_jobs():
last_page = get_last_page()
jobs = extract_jobs(last_page)
return jobs
so.py
import requests
from bs4 import BeautifulSoup
URL = f"https://stackoverflow.com/jobs?q=python&sort=i"
def get_last_page():
result = requests.get(URL)
soup = BeautifulSoup(result.text, "html.parser")
pages = soup.find("div", {"class": "s-pagination"}).find_all("a")
last_page = pages[-2].get_text(strip=True)
return int(last_page)
def extract_job(html):
title = html.find("div", {"class": "fl1"}).find("h2").find("a")["title"]
company, location = html.find("div", {
"class": "fl1"
}).find("h3").find_all("span")
company = company.get_text(strip=True)
location = location.get_text(strip=True)
job_id = html["data-jobid"]
return {
"title": title,
"company": company,
"location": location,
"link": f"https://stackoverflow.com/jobs/{job_id}"
}
def extract_jobs(last_page):
jobs = []
for page in range(last_page):
#print(f"Scrapping SO page:{page}")
result = requests.get(f"{URL}&pg = {page+1}")
soup = BeautifulSoup(result.text, "html.parser")
results = soup.find_all("div", {"class": "-job"})
for result in results:
job = extract_job(result)
jobs.append(job)
return jobs
def get_jobs():
last_page = get_last_page()
jobs = extract_jobs(last_page)
return jobs준비가 다됐다. 그럼 이제 csv파일을 만들어보자.
CSV파일이란?
엑셀과 같은 행렬(matrix)구조로 데이터를 표현, 저장을 위한 포멧이다..xls 파일은 microsoft 엑셀이 있어야만 열 수 있다. 엑셀과 같은 모든 데이터 시트에서 열기 위해서 .csv 파일로 만들어준다.
main.py를 아래와 같이 수정해주고
from indeed import get_jobs as get_indeed_jobs
from so import get_jobs as get_so_jobs
from save import save_to_file
indeed_jobs = get_indeed_jobs()
so_jobs = get_so_jobs()
jobs = indeed_jobs + so_jobs
save_to_file(jobs)save_to_file.py를 만들어 아래와 같이 작성하자
import csv
def save_to_file(jobs):
file = open("jobs.csv", mode="w")
writer = csv.writer(file)
writer.writerow(["title","company","location","link"])
for job in jobs:
writer.writerow(list(job.values()))
return열의 구분은 ,콤마로 한다. 실행을 시켜보면
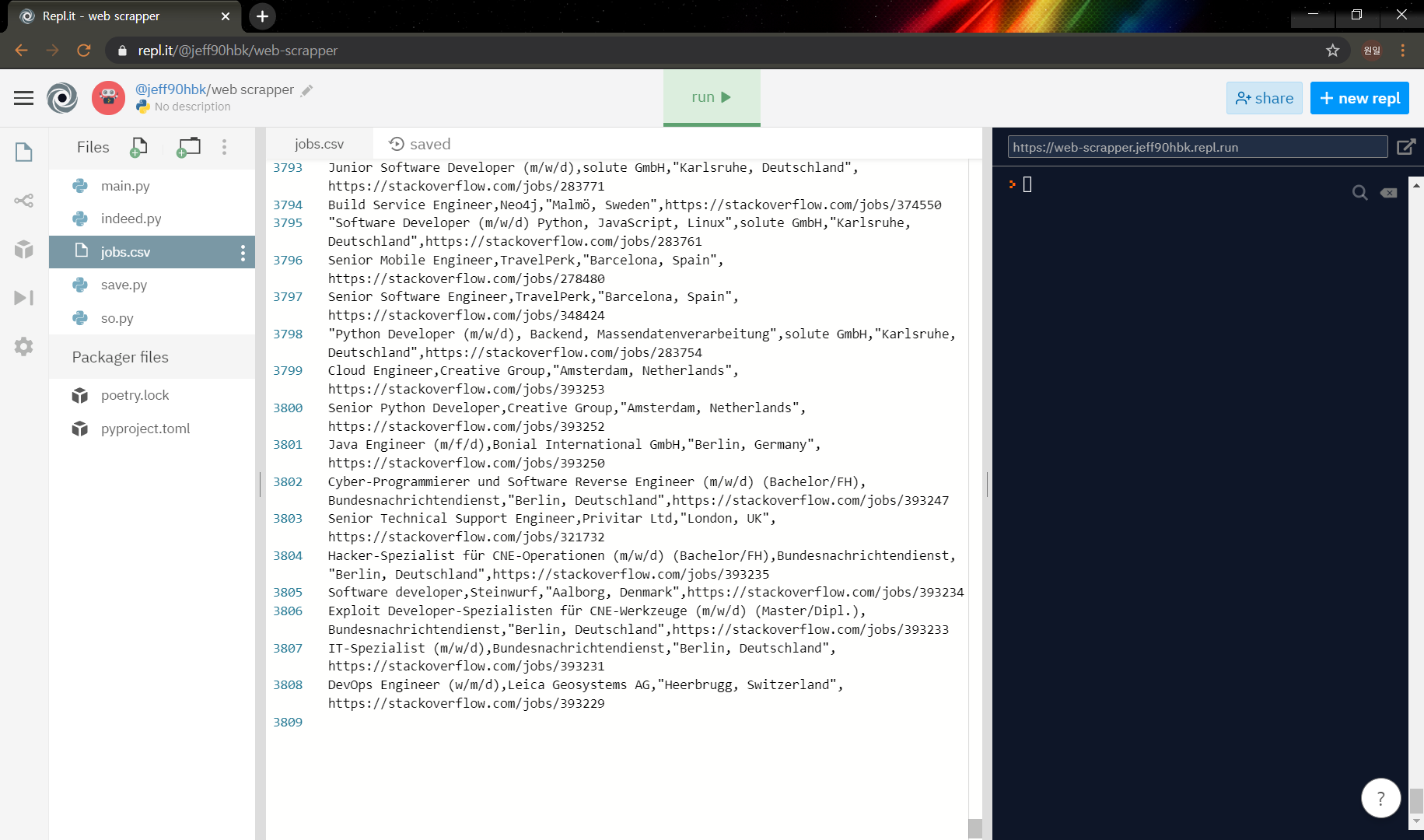
와우... 3808개의 채용정보가 스크래핑 됐다!
*_repl it *_을 굳이 사용할필요는 없었는데, 니꼬의 강의가 repl it으로 진행돼서 우선은 따라했다.
vscode로 옮겨보자.
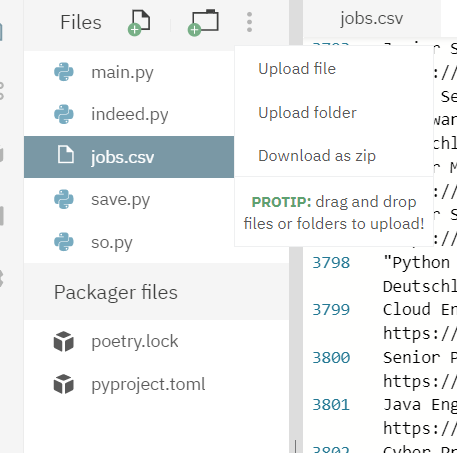
... 표시를 누르고 Download as zip을 누르자.
(WSL 에 저장할 것이므로 링크복사를 했다.)
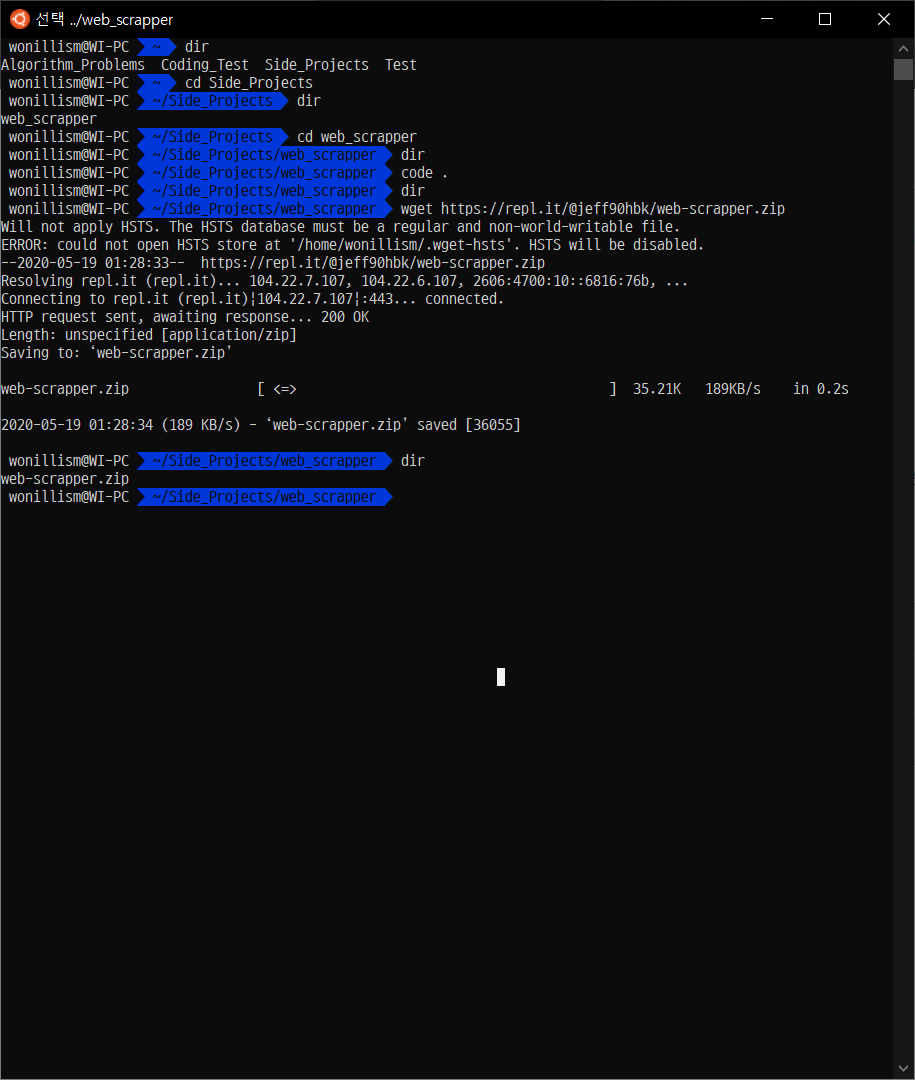
wget - 다운받을링크를 하면 해당 디렉토리에 파일을 다운받을 수 있다.
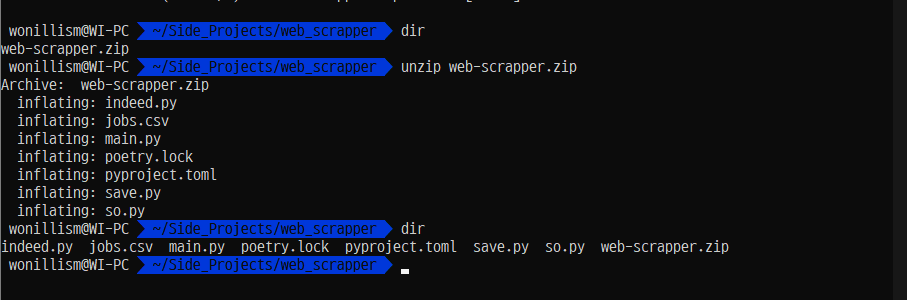
unzip을 통해서 압축을 풀어주자.
csv 파일을 좀 더 편하게 보고, 미리보기를 위해서 extension인 rainbow csv를 설치하자.
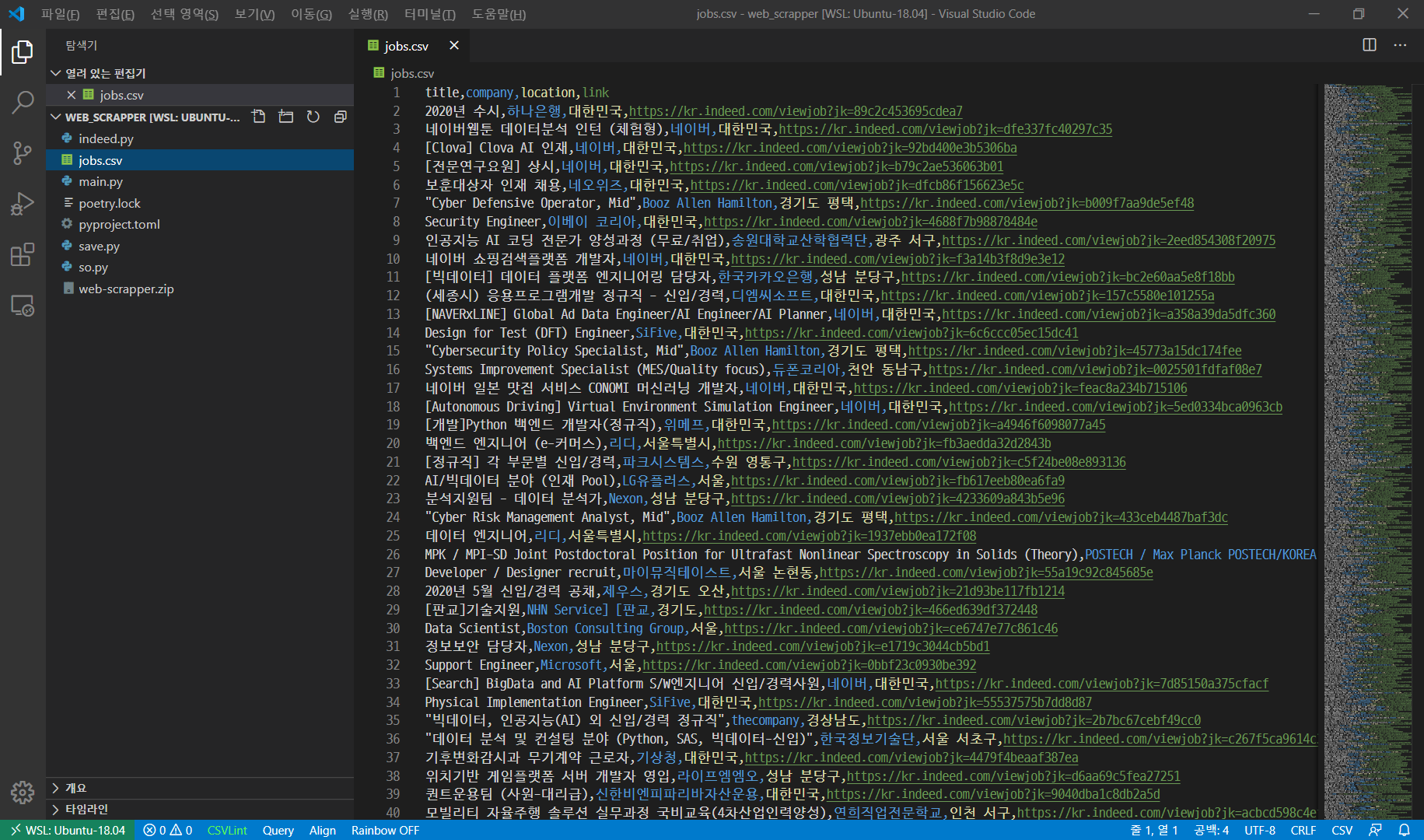
이렇게 알록달록한 csv를 볼수 있다. 미리보기기능도 제공한다.
안된다.. 뭐 너무 작다고 오류창이 뜬다.
ctrl + shift + p를 눌러서 명령 팔레트를 키고 rbql을 입력해서 실행시키자.

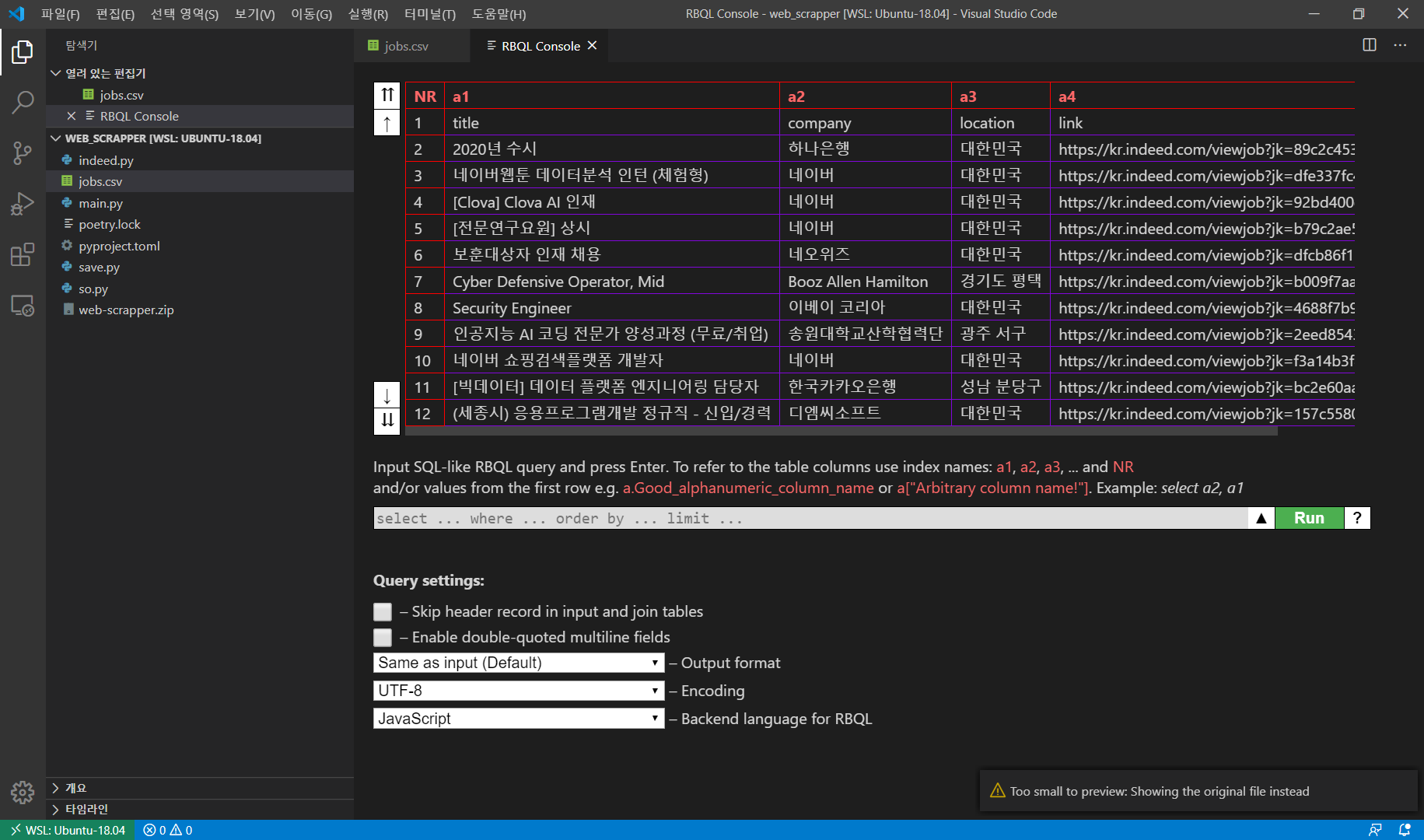
아래 sql 명령문으로도 조작이 가능하다. 싱기방기~~
구글 스프레드 시트에서 열어보자
파일열기 -> 업로드 -> drag and drop
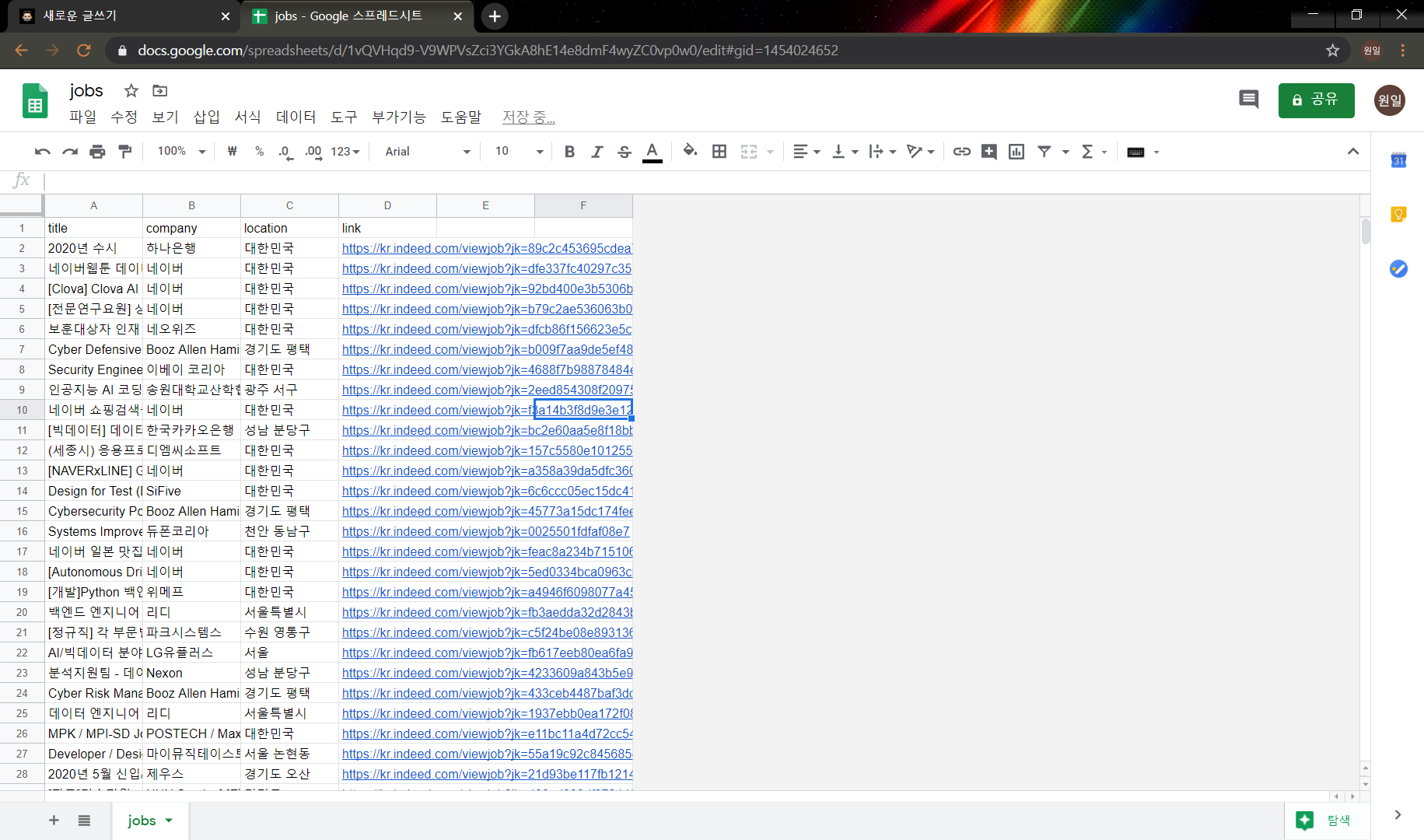
짜란~~
니꼬의 파이썬으로 웹 스크래퍼 만들기 절반 수강~
https://academy.nomadcoders.co/courses/enrolled/681401
Python으로 웹 스크래퍼 만들기
Python for Absolute Beginners
academy.nomadcoders.co
이전까지 indeed의 정보들을 가지고왔다면 이번에는 stackoverflow의 정보들을 가져오고 main.py를 수정해서 csv파일을 만들 준비를 하자.
main.py
from indeed import get_jobs as get_indeed_jobs
from so import get_jobs as get_so_jobs
from save import save_to_file
indeed_jobs = get_indeed_jobs()
so_jobs = get_so_jobs()
indeed.py
import requests
from bs4 import BeautifulSoup
LIMIT = 50
URL = f"https://kr.indeed.com/jobs?q=python&limit={LIMIT}"
def get_last_page():
result = requests.get(URL)
soup = BeautifulSoup(result.text, "html.parser")
pagination = soup.find("div", {"class": "pagination"})
links = pagination.find_all('a')
pages = []
for link in links[:-1]:
pages.append(int(link.string))
max_page = pages[-1]
return max_page
def extract_job(html):
title = html.find("h2", {"class": "title"}).find("a")["title"]
company = html.find("span", {"class": "company"})
company_anchor = company.find("a")
if company_anchor is not None:
company = str(company_anchor.string)
else:
company = str(company.string)
company = company.strip() # 빈칸을 지워줌
location = html.find("div", {"class": "recJobLoc"})["data-rc-loc"]
job_id = html["data-jk"]
return {
"title": title,
"company": company,
"location": location,
"link": f"https://kr.indeed.com/viewjob?jk={job_id}"
}
def extract_jobs(last_page):
jobs = []
for page in range(last_page):
#print(f"Scrapping indeed page:{page}")
result = requests.get(f"{URL}&start={page*LIMIT}")
soup = BeautifulSoup(result.text, "html.parser")
results = soup.find_all("div", {"class": "jobsearch-SerpJobCard"})
for result in results:
job = extract_job(result)
jobs.append(job)
return jobs
def get_jobs():
last_page = get_last_page()
jobs = extract_jobs(last_page)
return jobs
so.py
import requests
from bs4 import BeautifulSoup
URL = f"https://stackoverflow.com/jobs?q=python&sort=i"
def get_last_page():
result = requests.get(URL)
soup = BeautifulSoup(result.text, "html.parser")
pages = soup.find("div", {"class": "s-pagination"}).find_all("a")
last_page = pages[-2].get_text(strip=True)
return int(last_page)
def extract_job(html):
title = html.find("div", {"class": "fl1"}).find("h2").find("a")["title"]
company, location = html.find("div", {
"class": "fl1"
}).find("h3").find_all("span")
company = company.get_text(strip=True)
location = location.get_text(strip=True)
job_id = html["data-jobid"]
return {
"title": title,
"company": company,
"location": location,
"link": f"https://stackoverflow.com/jobs/{job_id}"
}
def extract_jobs(last_page):
jobs = []
for page in range(last_page):
#print(f"Scrapping SO page:{page}")
result = requests.get(f"{URL}&pg = {page+1}")
soup = BeautifulSoup(result.text, "html.parser")
results = soup.find_all("div", {"class": "-job"})
for result in results:
job = extract_job(result)
jobs.append(job)
return jobs
def get_jobs():
last_page = get_last_page()
jobs = extract_jobs(last_page)
return jobs준비가 다됐다. 그럼 이제 csv파일을 만들어보자.
CSV파일이란?
엑셀과 같은 행렬(matrix)구조로 데이터를 표현, 저장을 위한 포멧이다..xls 파일은 microsoft 엑셀이 있어야만 열 수 있다. 엑셀과 같은 모든 데이터 시트에서 열기 위해서 .csv 파일로 만들어준다.
main.py를 아래와 같이 수정해주고
from indeed import get_jobs as get_indeed_jobs
from so import get_jobs as get_so_jobs
from save import save_to_file
indeed_jobs = get_indeed_jobs()
so_jobs = get_so_jobs()
jobs = indeed_jobs + so_jobs
save_to_file(jobs)save_to_file.py를 만들어 아래와 같이 작성하자
import csv
def save_to_file(jobs):
file = open("jobs.csv", mode="w")
writer = csv.writer(file)
writer.writerow(["title","company","location","link"])
for job in jobs:
writer.writerow(list(job.values()))
return열의 구분은 ,콤마로 한다. 실행을 시켜보면
와우... 3808개의 채용정보가 스크래핑 됐다!
*_repl it *_을 굳이 사용할필요는 없었는데, 니꼬의 강의가 repl it으로 진행돼서 우선은 따라했다.
vscode로 옮겨보자.
... 표시를 누르고 Download as zip을 누르자.
(WSL 에 저장할 것이므로 링크복사를 했다.)
wget - 다운받을링크를 하면 해당 디렉토리에 파일을 다운받을 수 있다.
unzip을 통해서 압축을 풀어주자.
csv 파일을 좀 더 편하게 보고, 미리보기를 위해서 extension인 rainbow csv를 설치하자.
이렇게 알록달록한 csv를 볼수 있다. 미리보기기능도 제공한다.
안된다.. 뭐 너무 작다고 오류창이 뜬다.
ctrl + shift + p를 눌러서 명령 팔레트를 키고 rbql을 입력해서 실행시키자.
아래 sql 명령문으로도 조작이 가능하다. 싱기방기~~
구글 스프레드 시트에서 열어보자
파일열기 -> 업로드 -> drag and drop
짜란~~
니꼬의 파이썬으로 웹 스크래퍼 만들기 절반 수강~
https://academy.nomadcoders.co/courses/enrolled/681401
Python으로 웹 스크래퍼 만들기
Python for Absolute Beginners
academy.nomadcoders.co