
이제 긁어오는 방법을 알았으니 이것을 토대로 복습을 해볼것이다.
프로그래머스 코딩테스트 문제 중 내가 푼문제와 안 푼 문제를 보고싶을때가 있는데 프로그래머스는 확인할 수 가 없다.
그래서 내가 직접 긁어와서 필터링을 해보겠다.
Beautiful Soup 4 vscode에 설치하기
sudo apt-get update # 사용가능한 패키지들과 그 버전들의 리스트를 업데이트 하는 명령
sudo apt-get install python3-pip # python라이브러리 패키지 관리 시스템
pip3 install beautifulsoup4 # beautifulsoup4 설치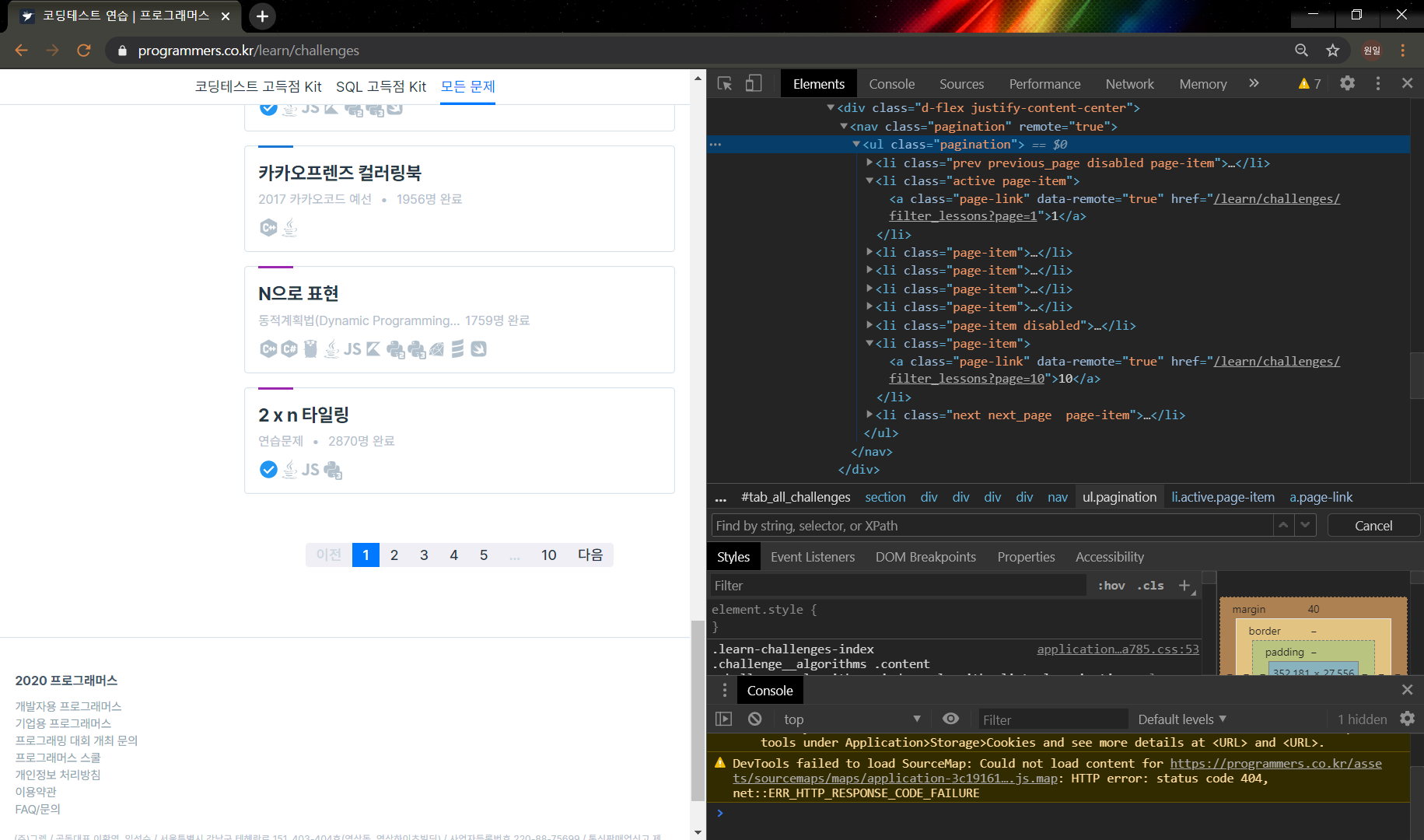
페이지 넘버를 우클릭하여 검사를 눌러보면 위와같이 pagination을 가진 태그를 찾을 수 있다.
그런데 문제가 생겼다. 분명 pagination\을 가져왔는데 결과는 None
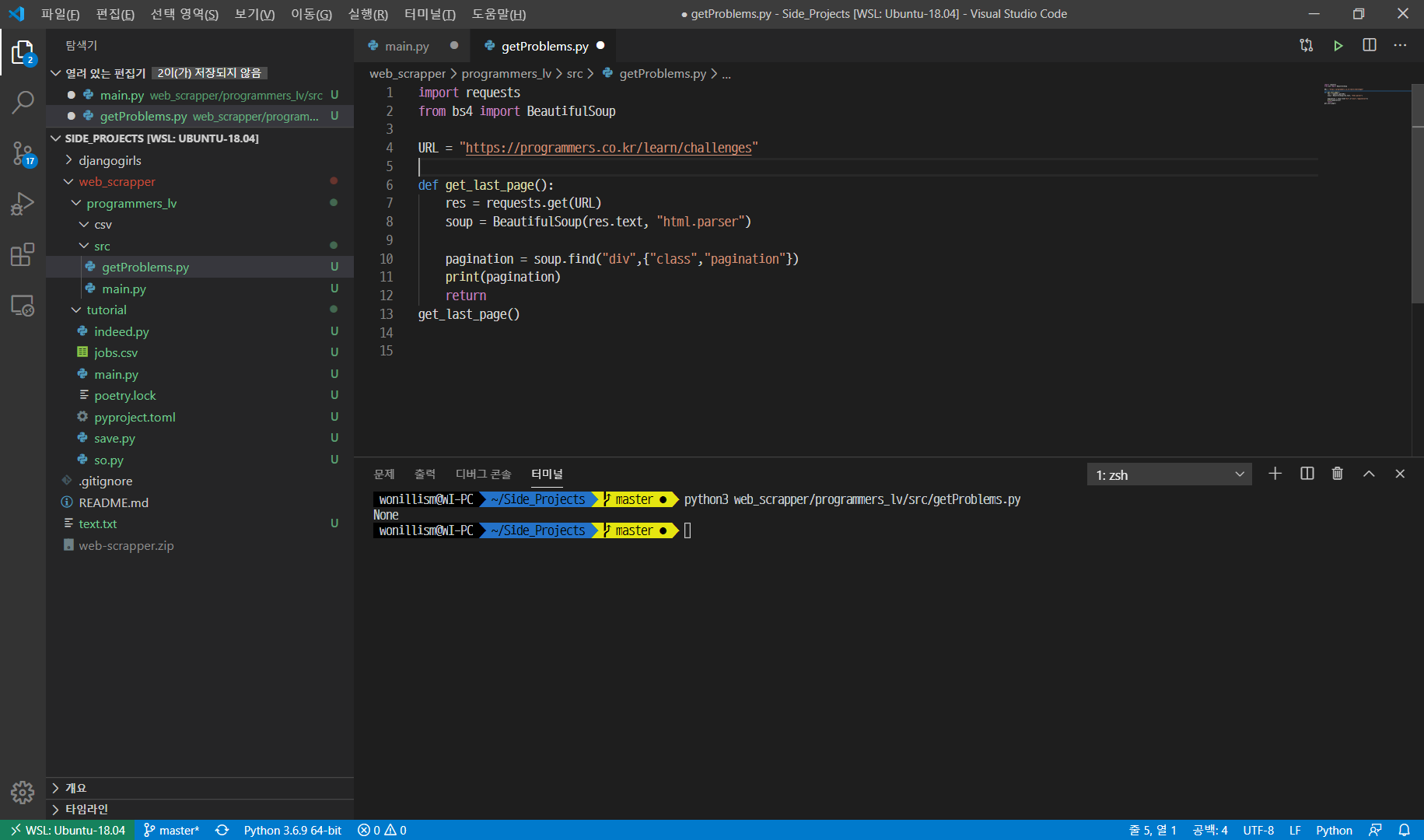
이유가 뭔지 싶어서 html.parser한 soup을 txt파일로 추출해봤다.
import requests
from bs4 import BeautifulSoup
URL = "https://programmers.co.kr/learn/challenges"
def get_last_page():
res = requests.get(URL)
soup = BeautifulSoup(res.text, "html.parser")
f = open("text.txt","w")
f.write(str(soup))
# pagination = soup.find("div",{"class","pagination"})
# print(pagination)
f.close()
return
get_last_page()
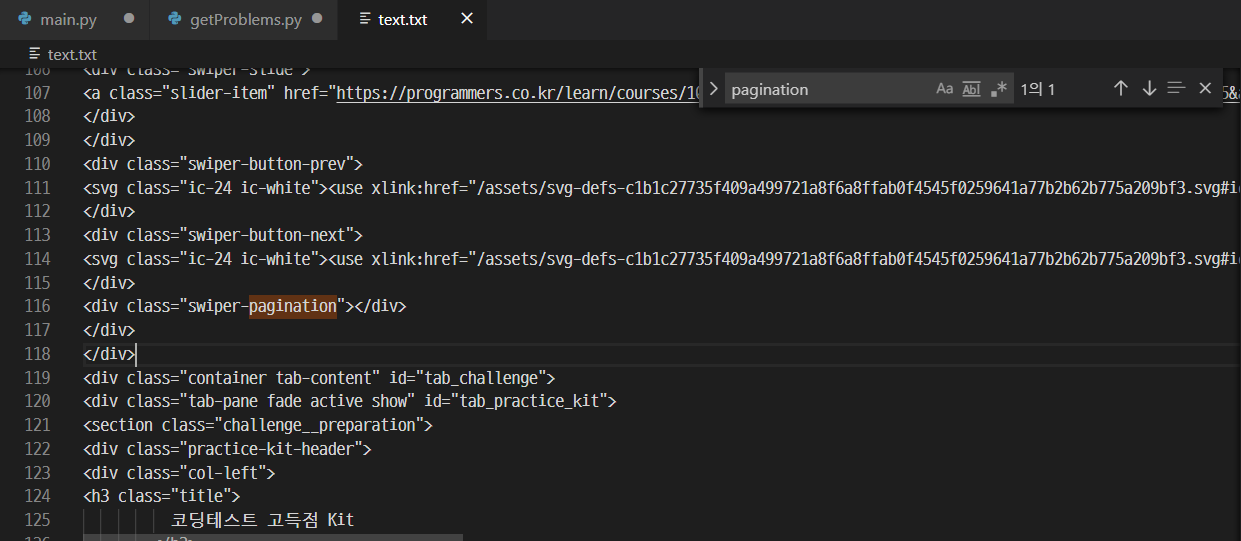
없다... 왜 없지 ㅠㅜ
swiper-pagination만 존재할뿐...
아마 동적으로 생성되는 코드라 정적인 값만 존재하는 html.parser에는 없는것같다
조금 구글링을 해보니 Selenium 이라는 프레임워크가 있었다.(해야하나...)
Selenium
Selenium은 주로 웹앱을 테스트하는데 이용하는 프레임워크다. webdriver라는 API를 통해 운영체제에 설치된 Chrome등의 브라우저를 제어하게 된다.
브라우저를 직접 동작시킨다는 것은 JavaScript를 이용해 비동기적으로 혹은 뒤늦게 불러와지는 컨텐츠들을 가져올 수 있다는 것이다. 즉, '눈에 보이는' 컨텐츠라면 모두 가져올 수 있다는 뜻이다. 우리가 requests에서 사용했던 .text의 경우 브라우저에서 '소스보기'를 한 것과 같이 동작하여, JS등을 통해 동적으로 DOM이 변화한 이후의 HTML을 보여주지 않는다. 반면 Selenium은 실제 웹 브라우저가 동작하기 때문에 JS로 렌더링이 완료된 후의 DOM결과물에 접근이 가능하다.
pip install selenium # 안된다면 아래 명령
pip3 install selenium chrome 설치하기
$ wget -q -O - https://dl-ssl.google.com/linux/linux_signing_key.pub | sudo apt-key add -
$ sudo sh -c 'echo "deb [arch=amd64] http://dl.google.com/linux/chrome/deb/ stable main" >> /etc/apt/sources.list.d/google.list'
$ sudo apt-get update
$ sudo apt-get install google-chrome-stable네 가지 커멘드를 순서대로 틀림없이 입력해주자.
여기까진 했는데... 안된다..............
모르겠다..
~복습도 아니고 이건 뭐... 시간만 날렸네 ~
2020-06-02 Updated
방법을 찾았다. 동적으로 생성되는 코드가 이유가 아니었다! 다만 숨겨뒀을 뿐이다. 갑자기 번뜩하고 생각나서 해봤는데 진짜 됐다.
내가 생각해낸 방법은 단순하지만 당연한? 거였다.

프로그래머스에서 코딩테스트 연습을 누르면 나오는 주소다. 주소를 잘 보면 [코딩테스트 연습] -> [모든문제]를 눌렀을때의 주소는 아래와 같다
https://programmers.co.kr/learn/challenges?tab=all\_challenges
이 주소를 크롤링 해보자!