우선 indeed의 파이썬 채용 공고를 스크래핑 할 것이다.
https://github.com/psf/requests
psf/requests
A simple, yet elegant HTTP library. Contribute to psf/requests development by creating an account on GitHub.
github.com
우선은 repl it 으로 진행할거라서 다른 방식으로 import 해야한다.
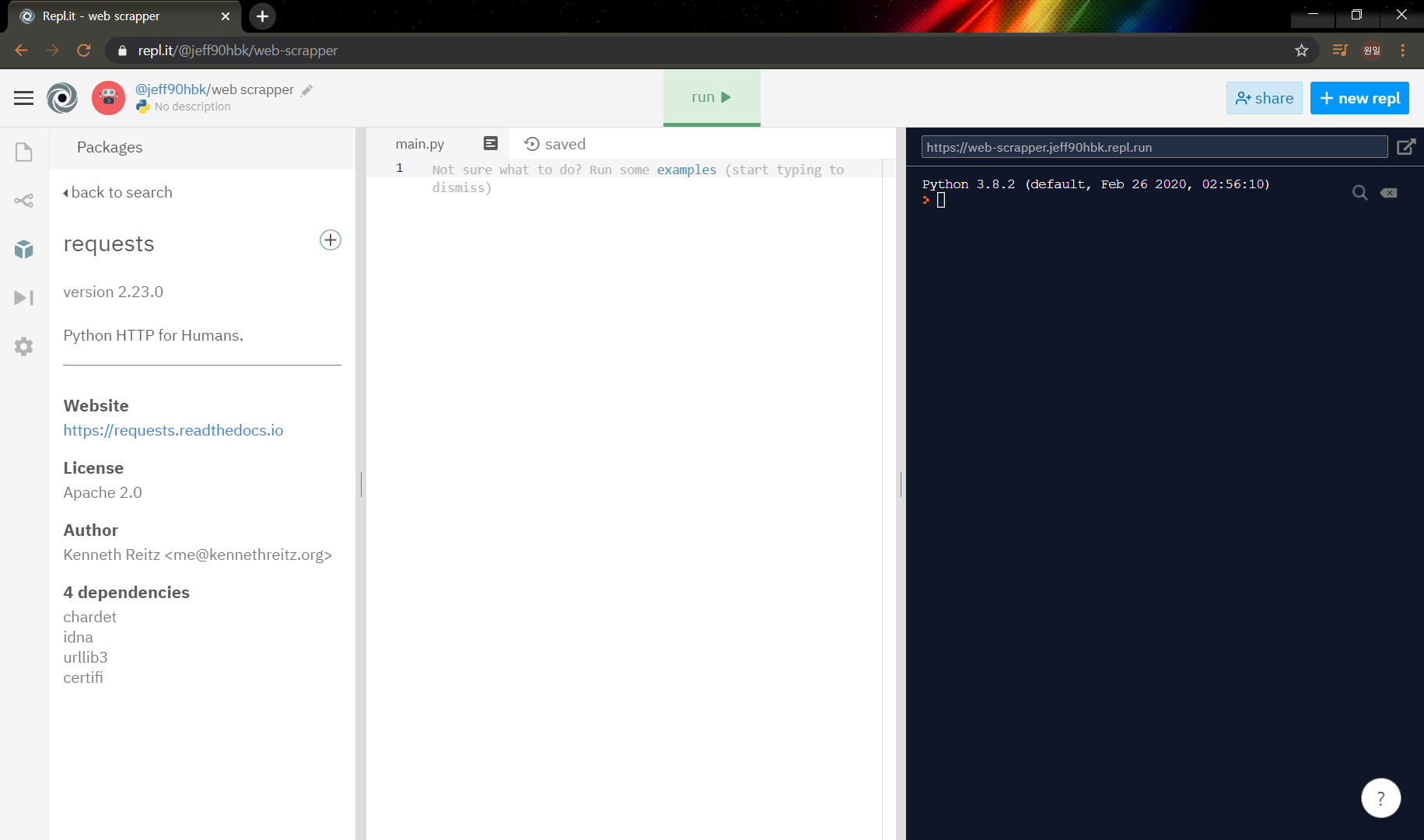
좌측의 박스모양인 packages를 누르고 requests *를 검색하고 *+ 버튼을 누르자.
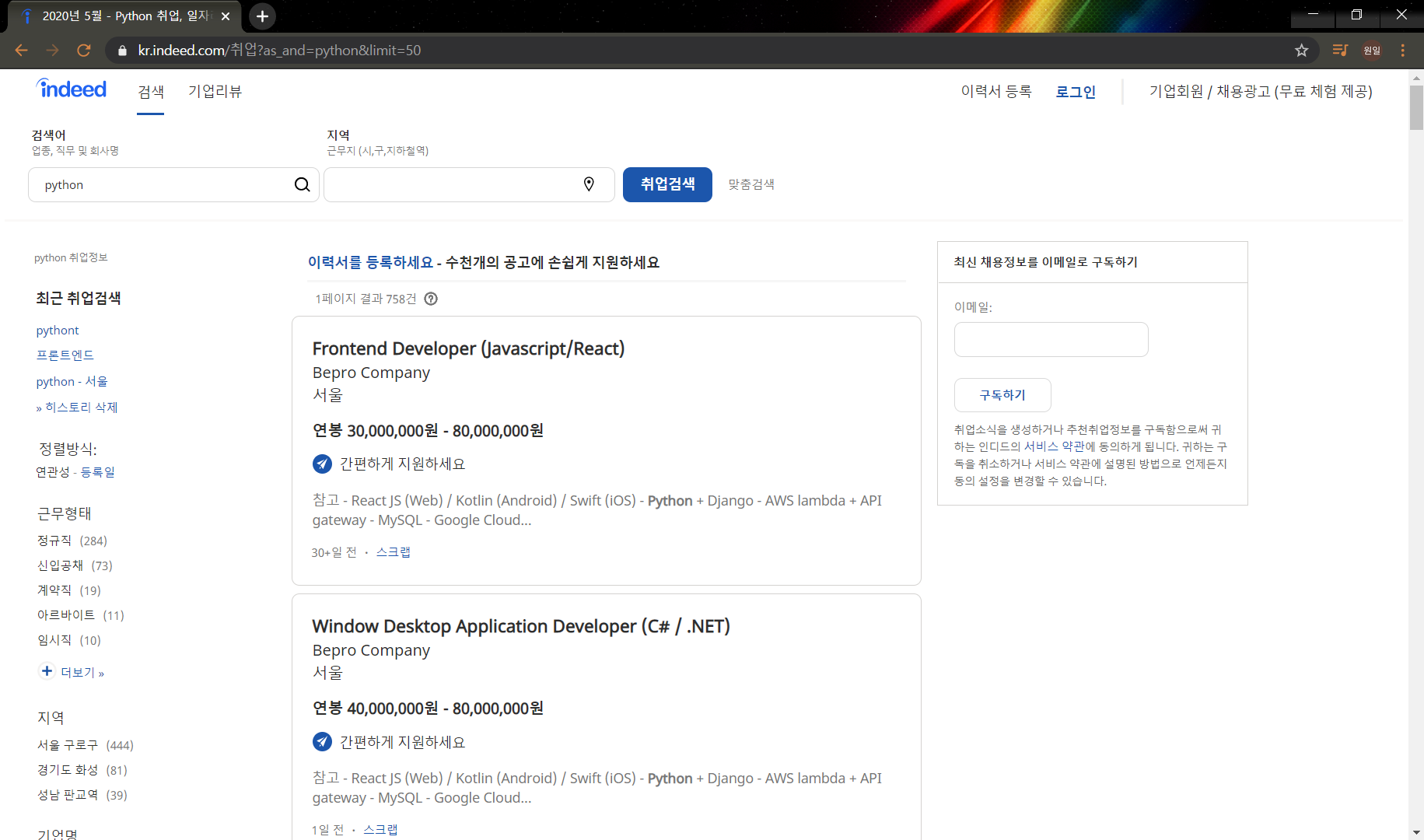
주소창을 잘 보면 아래와 같이 되어있는데, api 호출하면서 많이 봤던것들이다. *_python의 검색 결과 중 50개씩 보여주기 *_라는 뜻으로 보인다. (맞춤검색에서 N개씩 보기를 설정할 수 있다.)
https://kr.indeed.com/%EC%B7%A8%EC%97%85?as_and=python&limit=50그다음 main.py에 아래와 같이 입력해주면 성공~ <Response [200]> 이란걸 볼 수 있는데
응답상태 코드로서 MDN 에 잘 정리되어있다. 참고하자!
HTTP 상태 코드
번역이 완료되지 않았습니다. Please help translate this article from English HTTP 응답 상태 코드는 특정 HTTP 요청이 성공적으로 완료되었는지 알려줍니다. 응답은 5개의 그룹으로 나누어집니다: 정보를 제
developer.mozilla.org
이번에는 이 페이지의 html을 살펴보자.
print(indeed_result.text) 이렇게 바꾸고 run을 눌러보면 어마어마한 결과를 볼 수 있다.
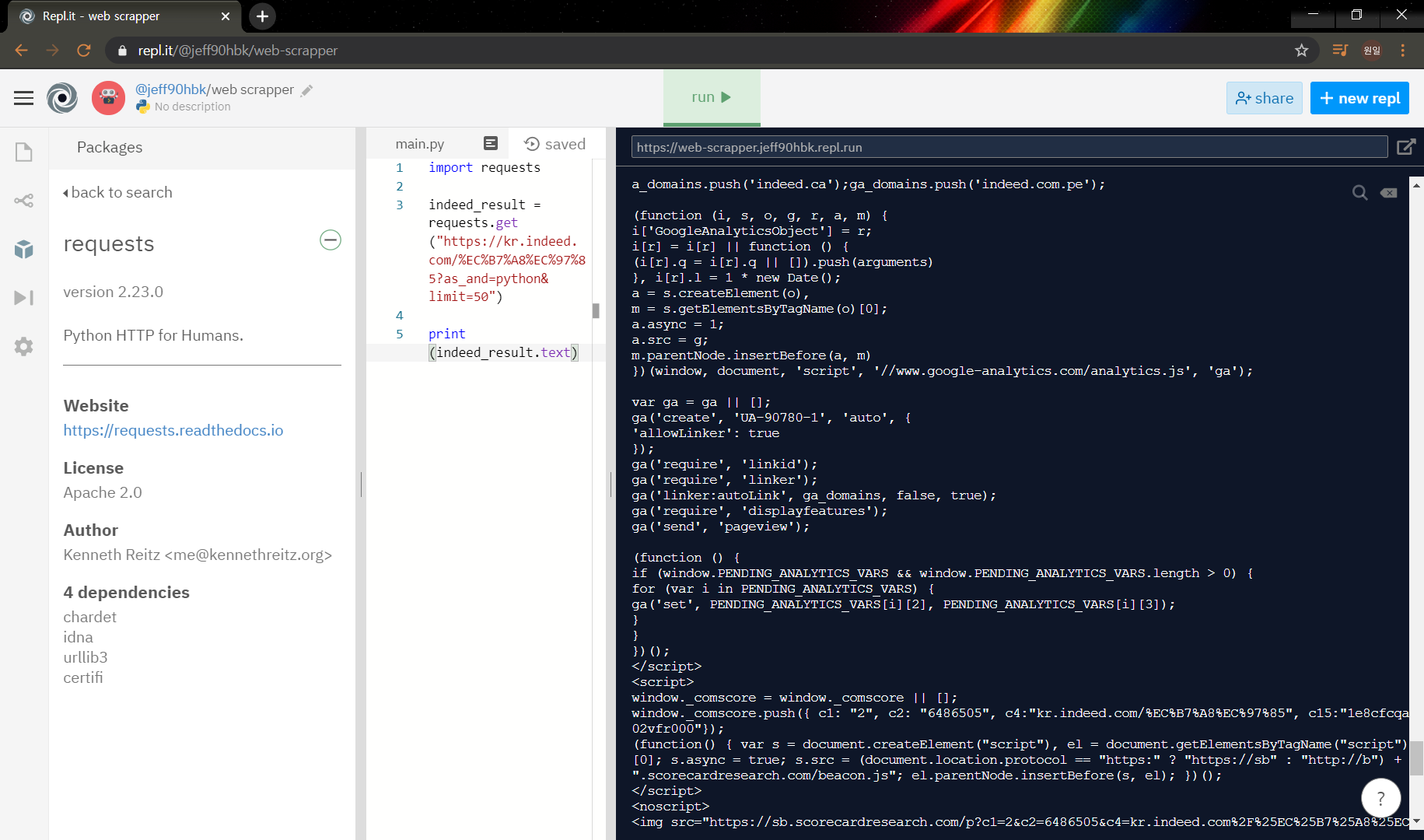
모든 html을 가져온 결과이다.
그 다음은 html에서 정보를 추출하기 좋은 package 를 깔아보자.
beautifulsoup4 라는 패키지이다.
아까와 마찬가지로 좌측 package > beautifulsoup4 검색 > +
import requests
from bs4 import BeautifulSoup
indeed_result = requests.get("https://kr.indeed.com/%EC%B7%A8%EC%97%85?as_and=python&limit=50")
indeed_soup = BeautifulSoup(indeed_result.text,"html.parser")
print(indeed_soup)위와 같이 입력하고 run을 눌러보면 역시 또 어마어마한 결과를 볼 수 있다.
beatifulsoup4으로 할 수 있는 간단한 예시는 아래와 같이 볼 수 있다.
beautiful soup Documentation 를 참조하자.
Beautiful Soup Documentation — Beautiful Soup 4.9.0 documentation
Non-pretty printing If you just want a string, with no fancy formatting, you can call unicode() or str() on a BeautifulSoup object, or a Tag within it: str(soup) # ' I linked to example.com ' unicode(soup.a) # u' I linked to example.com ' The str() functio
www.crummy.com
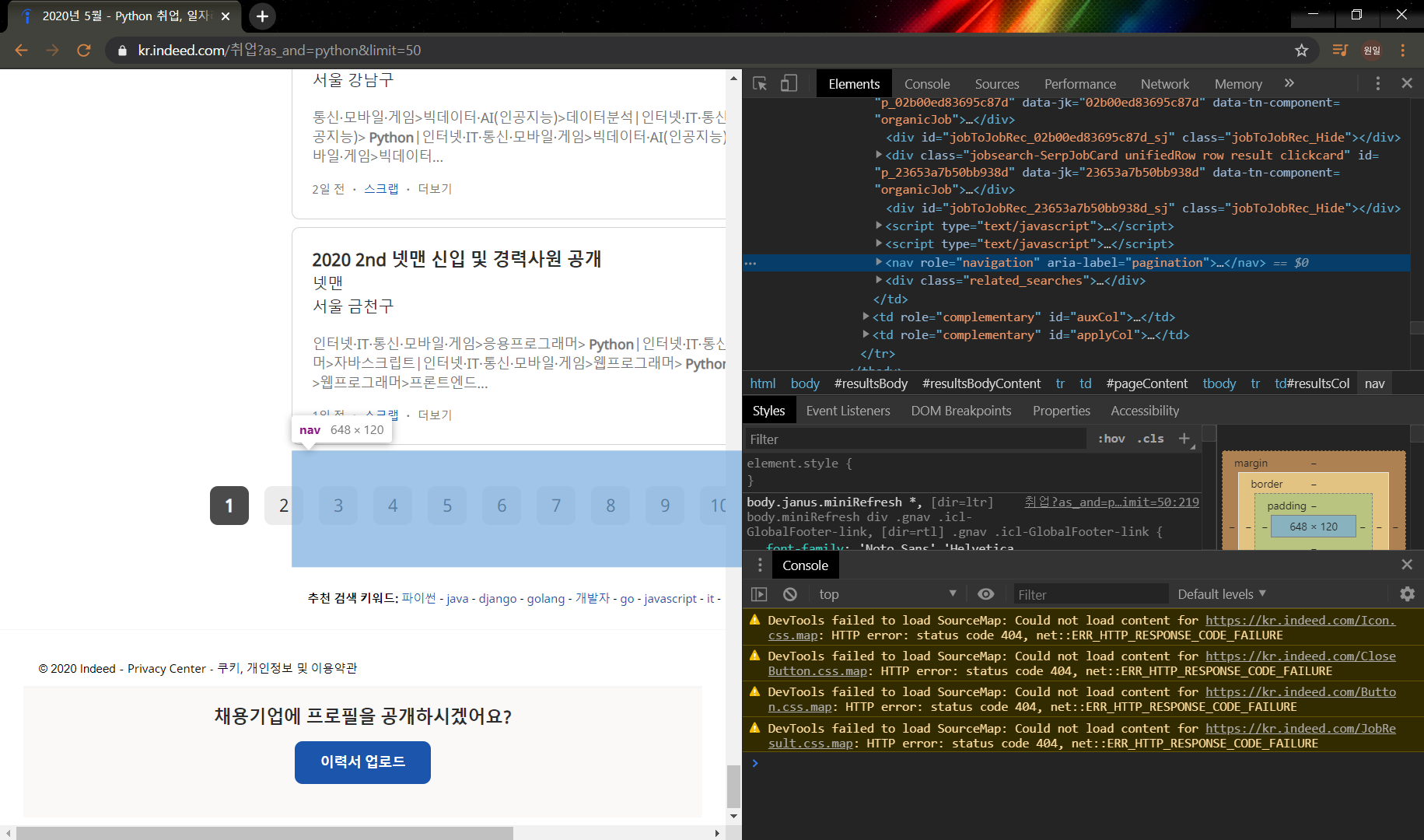
수 많은 html 코드 중에서 아래 page를 구분하는 코드를 찾아보자.
구글 검사를 들어가서 보면 그림과 같이 pagination이 있다.
import requests
from bs4 import BeautifulSoup
indeed_result = requests.get("https://kr.indeed.com/%EC%B7%A8%EC%97%85?as_and=python&limit=50")
indeed_soup = BeautifulSoup(indeed_result.text,"html.parser")
pagination = indeed_soup.find("div", {"class":"pagination"})
print(pagination)검사 탭을 확인해보면 또 많은 코드가... 잘 찾아보면 숫자로 분류되어있는 것들이 있다. 하단의 page를 구분하는 코드를 찾은것이다.
다음으로 이 코드들 중 anchor 안의 span을 찾아보자.
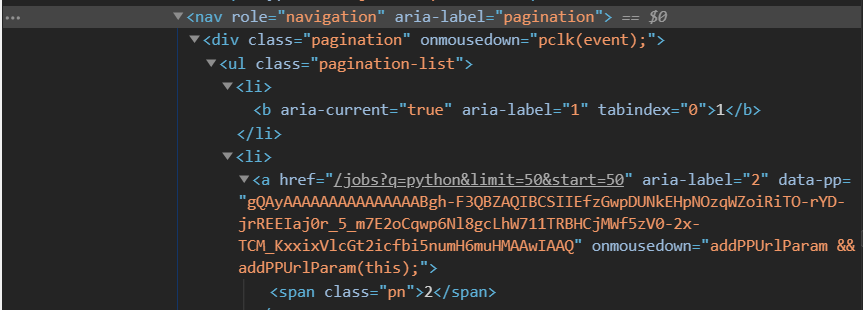
import requests
from bs4 import BeautifulSoup
indeed_result = requests.get("https://kr.indeed.com/%EC%B7%A8%EC%97%85?as_and=python&limit=50")
indeed_soup = BeautifulSoup(indeed_result.text,"html.parser")
pagination = indeed_soup.find("div", {"class":"pagination"})
pages = pagination.find_all('a')
print(pages)
for page in pages:
print(page.find("span"))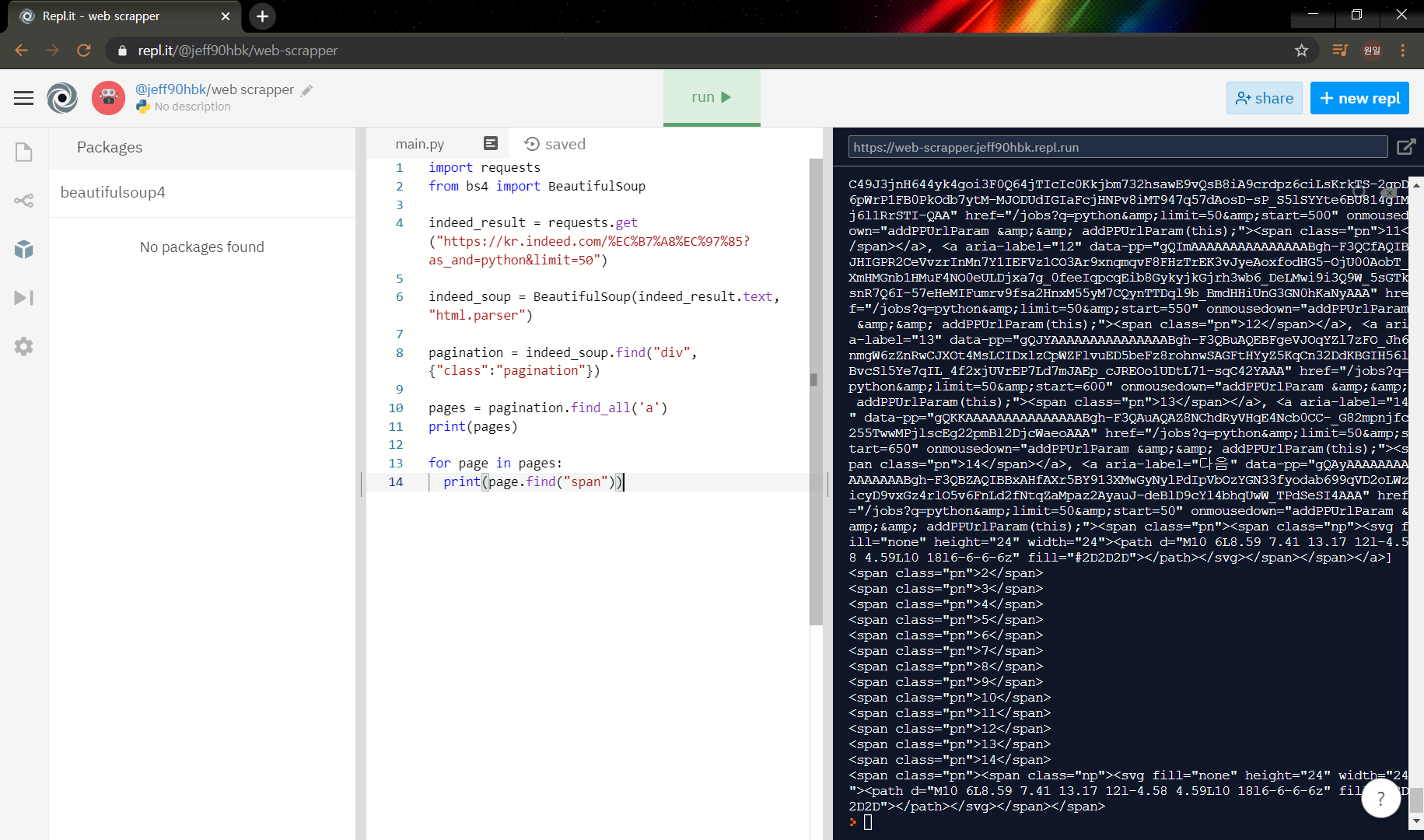
총 14페이지 까지 있고 다음 페이지 버튼을 의미하는 pn까지 출력됐다. Cooooooooooool~
이 span 값들을 빈 리스트에 저장하고 다시 출력해보자. 이때 맨 마지막 다음 버튼을 의미하는 것은 빼고 넣자.
import requests
from bs4 import BeautifulSoup
indeed_result = requests.get("https://kr.indeed.com/%EC%B7%A8%EC%97%85?as_and=python&limit=50")
indeed_soup = BeautifulSoup(indeed_result.text,"html.parser")
pagination = indeed_soup.find("div", {"class":"pagination"})
pages = pagination.find_all('a')
spans =[]
for page in pages:
spans.append(page.find("span"))
print(spans[:-1])
검사 탭을 잘 봤더니 span이 아닌 ul로 pagination-list 가 작성되어있었다. 그리고 어짜피 anchor안에 string이 하나 씩 뿐이어서 ul을 거치지 않아도 바로 찾을 수 있다.
그리고 찾은 페이지 넘버를 int형으로 바꿔주자.
import requests
from bs4 import BeautifulSoup
indeed_result = requests.get("https://kr.indeed.com/%EC%B7%A8%EC%97%85?as_and=python&limit=50")
indeed_soup = BeautifulSoup(indeed_result.text,"html.parser")
pagination = indeed_soup.find("div", {"class":"pagination"})
links = pagination.find_all('a')
pages =[]
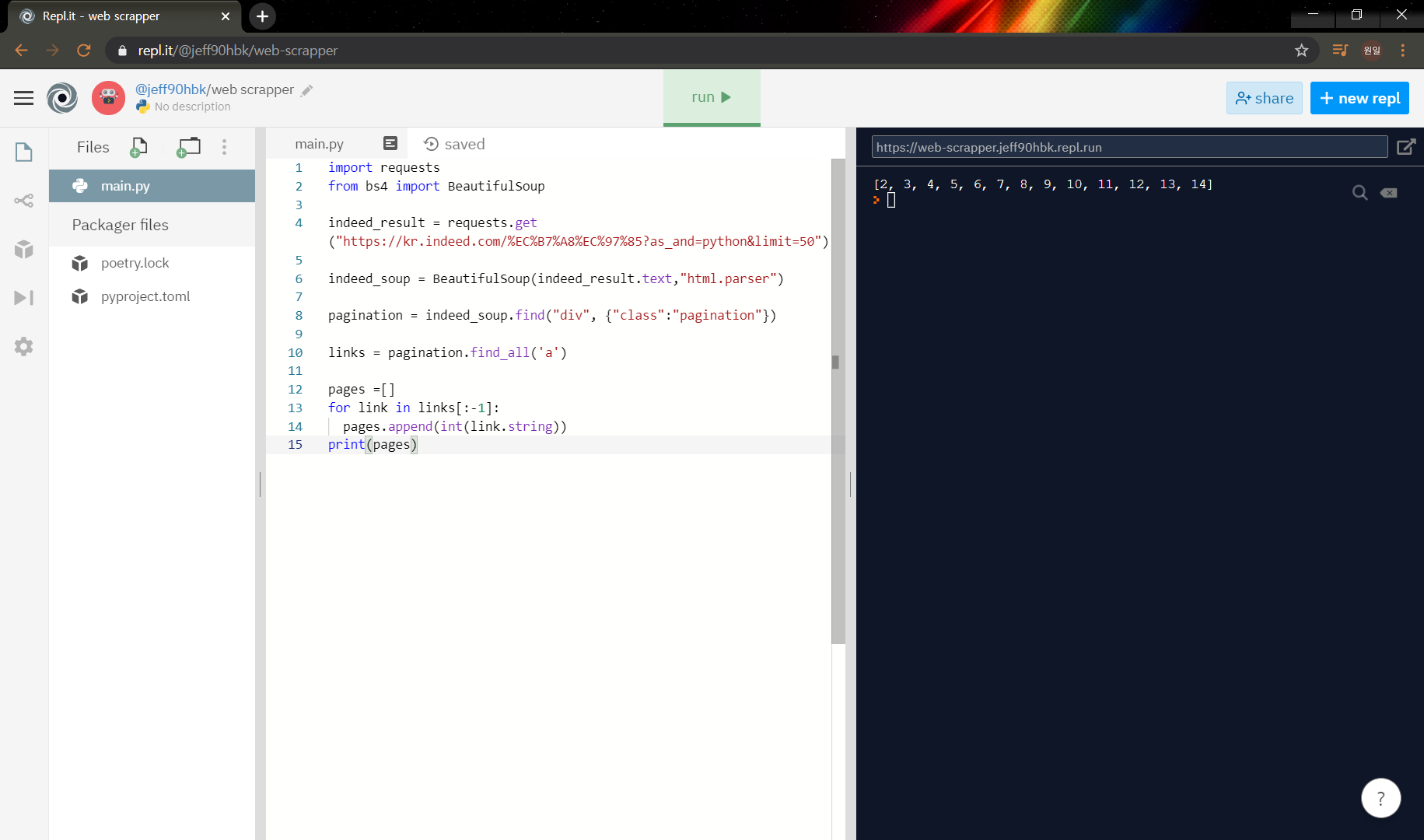
for link in links[:-1]:
pages.append(int(link.string))
print(pages)